Kapitola 6 Databázové systémy pro GIS
6.1 Přístupy ke zpracování údajů na počítačích
6.1.1 Agendové zpracování souborů
První systémy pro zpracování údajů na počítačích byly vyvíjeny tak, aby poskytovaly dobře definovaný soubor funkcí pro použití se specifickým souborem dat. Údaje byly ukládány jako jeden nebo více počítačových souborů, které byly přístupné pomocí softwaru specializovaného pro tento účel. Takový přístup je nazýván agendové zpracování souborů.
Agendové zpracování souborů je vhodné pro některé specifické účely, pro jiné má však vážné nedostatky. Každý aplikační uživatelský program musí přímo přistupovat do každého datového souboru, který využívá, musí poznat, jak jsou data v každém souboru uložena. To je zdrojem významné redundantnosti, neboť instrukce pro přístup do datových souborů musí být přítomné v každém aplikačním programu. Dojde-li k modifikaci struktury datového souboru, musí se modifikovat i instrukce přístupu ve všech aplikačních programech nebo naopak.
- Redundance (nadbytek dat): představte si např. kolikrát a v kolika souborech mohou být v rámci jednoho městského úřadu uložena jména a adresy obyvatel (matrika, stavební úřad atd.). Takováto duplicita vede k mrhání množstvím vstupů a výpočetními kapacitami.
Další vážný problém nastává při sdílení dat různými, rozdílnými aplikacemi a uživateli. V tomto případě by měla existovat určitá celková kontrola, přes kterou by byl uživatelům dán přístup k datům a která by určovala, jaké změny mohou s daty provádět. Nepřítomnost takové kontroly vážně ohrožuje integritu (i kvalitu) dat. V případech sdílení údajů více aplikacemi a uživateli dochází tedy ke ztrátě jejich integrity, nezávislosti a bezpečnosti.
- Nedostatečná integrita dat: Tam, kde jsou data ukládána více než jednou, objevuje se možnost, že jednotlivé kopie nebudou shodné. Při jednom průzkumu v určitém místním úřadu bylo např. objeveno deset kopií mapy stezek v „konečné podobě“, z nichž každá byla uložena v jiném oddělení, obsahovala jiné stezky a jen jedna z nich byla pravidelně aktualizována. Občané mají tendenci považovat úřady a organizace za jednolité celky, tj. stane-li se slečna Nováková paní Horákovou a informuje bytový úřad o této šťastné události, nebude asi příliš nadšena, bude-li jí Finanční úřad zasílat dopisy na jméno slečna Nováková.
další problémy spojené s agendovým zpracováním dat:
- vysoké náklady na údržbu – aplikační programy mají tendenci k individuálnímu (někdy až výstřednímu) stylu, protože často pracují v různých operačních systémech a jsou napsány v různých jazycích, musí mít organizace na jejich údržbu aplikační specialisty
- nedostatek shodných rozhraní – různé aplikace mohou pocházet z různých zdrojů a mít tedy i různá uživatelská rozhraní, výsledkem pak je malá pravděpodobnost, že budou aplikace spolu navzájem spolupracovat
- „vylepšení“ ad hoc – aplikační programy jsou obvykle uzpůsobeny k tomu, aby splňovaly požadavky platné v době zadání zakázky na dotyčný software. Spolu s rozvojem organizací se však požadavky na aplikace mohou měnit a může vzniknout celá řada ad hoc „slátanin“, které byly vytvořeny za účelem rozšíření aplikačních programů na nové oblasti
- problémy sdílení dat – vzhledem k tomu, že agendové zpracování souborů klade hlavní důraz na aplikace, dochází k tomu, že mají některé aplikace tendenci ovlivňovat datové struktury, takže pro jiné aplikace může být obtížné získat přístup k těmto datům
- nedostatek datových standardů
- nedostatečná ochrana – tam, kde existují vícenásobné kopie souborů, s malou mírou centrálního řízení, existuje vždy možnost, že data pokládaná za důvěrná, budou uvolněna do oběhu
- nedostatek společného pojetí a náhledu – u aplikačně orientované koncepce je obtížné zajistit, aby se uchovávání informací a počítačové systémy vyvíjely způsobem, který je optimální pro organizaci (na rozdíl od toho, co může být optimálním pro jednotlivá oddělení v rámci organizace)
6.1.2 Databázová koncepce
Výše zmíněné problémy agendového zpracování dat řeší tzv. databázový přístup ke zpracování údajů. V tomto případě jsou data uložena ve strukturované bázi dat, kterou spravuje systém řízení báze dat (database management system) - DBMS, který obsahuje soubor programů, jejichž úkolem je manipulace a obhospodařování údajů v databázi. Tyto programy byly navrženy tak, aby byla zajištěna integrita obhospodařované databáze. Báze dat je navržena tak, aby byla minimalizována její redundance, je zabezpečena nezávislost aplikačních programů na formě uložení dat. DBMS tedy působí jako ústřední, centrální řízení nad všemi interakcemi mezi databází a aplikačními programy, pomocí kterých ji uživatelé využívají. Služby poskytované DBMS také výrazně zjednodušují vývoj nových aplikačních programů a využitelnost dat.
Požadavky na systém řízení báze dat:
- přístup k údajům pro všechny aplikace bez vícenásobného ukládání * současný přístup k datům pro více uživatelů
- různé vyhledávací metody
- ochrana dat před neoprávněným přístupem a před chybami hardwaru a softwaru
- prostředky pro centrální správu dat
- nezávislost aplikací na datech
- možnost vytvářet i složité datové struktury
- ukrytí mechanismu struktur a ukládání dat
6.2 Posloupnost designu databáze
Obrázek č. xx představuje zjednodušený model postupu, kterým prochází databázový projekt od svého počátku až po dokončení.
Předběžná analýza zahrnuje analýzu nákladů a výnosů, studie proveditelnosti, systémovou analýzu, stanovení potřeb uživatele apod. Rozhodnutí pokračovat v budování databáze následuje práce databázového projektanta, který vytváří logický design. Projektant se musí důkladně seznámit se strukturou používaných dat a vytvořit pak konceptuální datový model (identifikace entit, vztahy mezi entitami, atributy entit), který se stane základem vlastní databáze. Konceptuální datový model tak představuje logický seznam entit, atributů a vztahů mezi entitami, které bude databáze obsahovat. Je vytvářen tak, aby byl nezávislý na jakémkoliv softwarovém programu. Jeho účelem je poskytnou „prostý“ přehled o tom, jak má vypadat struktura dat ve vytvářené databázi.
Je-li úspěšně dokončen logický design, dalším stadiem, které následuje je překlad tohoto designu do zvoleného software SŘBD (design se „namapuje“ do software). Tato fáze zahrnuje zřízení datové struktury – struktury záznamů, jména polí a souborů, indexy a algoritmy, které budou reprezentovat v rámci software SŘBD konceptuální design.
Když už byl vytvořen fyzický návrh databáze, v další fázi je nutno zajistit, aby tento návrh skutečně fungoval, tj. aby poskytoval výstupy požadované uživateli. Nastupuje tedy fáze testování. Po něm následuje fáze implementace, kdy jsou do databáze vkládána provozní data, je sestavována dokumentace pro uživatele a ti jsou také školeni. Vzhledem k tomu, že se organizace využívající databáze nikdy nepřestávají vyvíjet, dochází k tomu, že se požadavky na databáze vyvíjejí spolu s organizacemi, kterým databáze slouží. Proto není zanedbatelná ani poslední fáze – aktualizace nebo rozšiřování databází, jejich údržba.
6.2.1 Databázové modely
Datový nebo databázový model je podle Schebera (1988) systém modelovacích prostředků používaných při modelování. Výsledkem je konkrétní organizace dat, reprezentující výsek reality.
Vývoj databázových systémů směřoval od síťového, přes hierarchický po nejrozšířenější relační model až k dnes se rozvíjejícímu modelu objektově orientovanému:
- hierarchický model - typy entit jsou v tomto modelu přísně mapovány na příkladu vztahu otec - syn. Struktura je formována jako soustava spojení všech záznamů ve formě stromu. Vrcholem hierarchie je kořen. Hierarchický model pouze vztahy typu 1:1 a 1:n mezi jednotlivými typy entit. Spojení existují jen mezi nadřízenými a podřízenými, neexistují spojení na té samé úrovni (jedna z největších nevýhod tohoto modelu). Pokud v hierarchickém modelu existuje relace m:n , musíme ji reprezentovat jako m-násobek relací 1:n. Velkou nevýhodou tohoto modelu vysoká redundantnost (opakované uložení týchž dat na různých místech) a určený postup dotazů, daný hierarchií, který je obtížné měnit. Hierarchické struktury se vyznačují vysokou rychlostí prohledávání, jsou snadno pochopitelné, lehce se aktualizují. Tento typ je používán např. v administrativě, pro bibliografické databáze nebo rezervační systémy v dopravě.
- síťový model - upouští od přísné hierarchie a mohou v něm existovat i relace typu m:n. Lze jej tedy chápat jako jakousi generalizaci hierarchického modelu. Jeho struktura je flexibilnější a méně redundantní než hierarchická. Musí se ukládat mnohem rozsáhlejší informace o propojeních mezi záznamy, což zvyšuje velikost a složitost datových souborů. Obhospodařování těchto přidaných údajů o propojeních je relativně časově náročné. Na jedné straně je tento model pružnější, na druhé se stává komplikovaným a chaotickým. Je používán např. při hledání nejlepšího spojení v komunikační síti. Poznámka: Hierarchická a síťová struktura jsou někdy označovány jako navigační, protože propojení v nich jsou konstruována pomocí vyhledávačů (pointer), které jsou používány i při navrhování aplikačních programů.
- relační model - jeho koncept se poprvé objevil během 70. let, je založen na matematickém přístupu – relaci. Byl motivován snahou popisovat data v jejich “přirozené” podobě a odbourat potřebu vytváření aplikačních programů nad databází s podrobnou znalostí formátu uložení dat. Ve srovnání se výše zmíněnými vyniká jednoduchostí. Základní a jedinou strukturou je tabulka (relace), do níž se data ukládají. Proto jsou někdy relační databáze nazývány také tabulkovými databázemi. V tabulce každá řádka odpovídá jednomu prvku (záznam - record). Ve sloupcích jsou ukládány hodnoty jednotlivých atributů (položka - item). Každá tabulka je obvykle ukládána jako samostatný soubor. Redundantost dat je zde mnohem menší než u hierarchického a síťového modelu. V tomto modelu neexistuje žádná hierarchie polí uvnitř záznamu, každé pole může být klíčem pro přístup k datům v jiné tabulce. Vzhledem k tomu, že v tabulkách nejsou žádné adresní údaje, je vyhledávání záznamů nebo polí sekvenční, proto je pomalejší než v hierarchickém nebo síťovém modelu. Jako stupeň relace označujeme počet jejich atributů. Všechny možné asociace (1:1, 1:n, m:n) mezi typy entit jsou reprezentovány pomocí klíčů. Klíč je obecně unikátní atribut nebo kombinace atributů. Klíče mají v relačním datovém modelu dvě důležité úlohy:
- slouží jako vyhledávače mezi různými relacemi, tj. spojují tabulku s jinou tabulkou,
- slouží k jednoznačné identifikaci entit – tzv. primární klíče (musí mít dvě vlastnosti: je jednoznačný, je minimální – není možné žádný atribut vypustit, aby se neporušilo pravidlo jednoznačnosti).
Operace, které lze vykonávat s relacemi dělíme do dvou základních skupin:
- relační algebra,
- relační kalkul.
Operace ukládání a vyhledávání dat v databázi jsou založeny na pravidlech a funkcích definovaných v matematické teorii relační algebry. Vyhledávání atributů, které k sobě patří a jsou uloženy v různých tabulkách se provádí spojením tabulek, které obsahují stejnou hodnotu klíče. Tato procedura se nazývá relační propojení. Propojení vytváří novou tabulku z dat vybraných tabulek, která může zůstat jen virtuální a nemusí být v databázi fyzicky uložena. Typ příkazu k vyhledávání dat není nijak omezen. Do relační algebry patří sjednocení, průnik, množinový rozdíl, symetrický rozdíl a kartézský součin.
Sjednocením relací vytváříme novou tabulku, která obsahuje všechny řádky obou vstupních tabulek. Pokud mají tyto tabulky některé řádky shodné, ve výstupní tabulce se objeví jen jednou. Průnikem vytvoříme tabulku, která bude obsahovat pouze řádky shodné pro obě vstupní tabulky. Množinovým rozdílem vytvoříme tabulku, ve které budou všechny řádky první vstupní tabulky, ale jen ty, které se nevyskytují v tabulce druhé. Symetrickým rozdílem vytvoříme tabulku, ve které budou všechny řádky obou tabulek, kromě těch, které se vyskytují v obou tabulkách současně. Kartézský součin vytvoří novou tabulku tak, že spojuje řádky z obou dvou tabulek systémem každý s každým.
K operacím relačního kalkulu patří projekce, selekce a spojení. Projekcí vzniká nová tabulka tak, že se ze vstupní tabulky vyberou určené sloupce. Ve vzniklé tabulce jsou pak zrušeny všechny duplicitní řádky. Selekcí vznikne tabulka se stejným záhlavím jako vstupní tabulka, ale menším počtem řádků. Řádky jsou vybírány podle některého atributu, jehož hodnoty se porovnávají s jiným řádkem nebo konstantou. Spojení (join) můžeme chápat jako vytvoření určité podmnožiny kartézského součinu vstupních tabulek. Oproti kartézskému součinu se spojení dvou tabulek vykoná pouze tehdy, je-li splněna definovaná podmínka pro spojení. Tou je výraz, ve kterém jsou porovnávány dva atributy z obou vstupních tabulek.
Nástrojem pro dosažení kvalitnější struktury dat je normalizace. Cílem normalizace je zpřesnit obraz reality v datech. Jde v podstatě o snahu zachovat soulad mezi konceptuálním a logickým modelem dat zhruba podle pravidla „pro každý objekt jeden záznam“. Takové záznamy jsou pak označovány jako normalizované. V praxi mají význam především první tři normální formy. Existují i další normální formy.
Nenormalizovaný záznam může často obsahovat jednu nebo více skupin položek, které se opakují a nejsou součástí klíče.
- Objektově orientovaný model - je odvozen na 5 zásadách, odvozených na základě zkušeností s jinými typy logických datových modelů:
- Každá entita je modelována jako objekt s vlastní identitou, která je poskytována objektově orientovaným databázovým systémem (OODBMS).
- Každý objekt je zapouzdřený (encapsulated), tj. chráněný proti prostředí a má vlastní strukturu (atributy) a vlastní chování (metody), tzn. že objekt je funkční (nemusíme se více zajímat o jeho interní procedury, ale jen o jeho chování vůči okolí).
- Objekty komunikují mezi sebou pomocí zpráv (pokud objekt dostane pochopitelnou zprávu, reaguje na ni plánovaným způsobem).
- Objekty se stejnými atributy a metodami vytvářejí třídy objektů, individuální objekt je nazýván příkladem.
- Třída objektů může být rozdělena na subtřídy specializací (odvozené třídy), které dědí atributy a metody nadtřídy (supertřídy).
V poslední době se dosti diskutuje o potřebě využívání a zavádění tohoto přístupu do strukturování informací obecně, ale i do GIS.
6.3 Organizace geografické databáze
Vzhledem k tomu, že prostorová (geometrická) i neprostorová (atributová) data jsou uložena v databázi, je problém organizace dat v GIS považován za problém “databázový”. Prostorová data jsou v GIS reprezentována uložením geometrie a k ní náležejících atributů. Jednotlivé systémy GIS se značně odlišují z hlediska způsobu ukládání dat a způsobu propojení atributů a prostorové (geometrické) části geografické databáze. Na základě těchto rozdílů lze vytvořit jednoduchou typologii systémů GIS:
- GIS „první generace“ (bez SŘBD)
- systémy bez souborů atributů – čistě rastrový přístup neumožňuje oddělení dat lokalizace a atributů (prostor je rozdělen do pravidelné sítě, každá buňka obsahuje hodnotu atributu, odpovídající umístění buňky, každá rastrová mapa uložena jako oddělený soubor) – např. „MAP“ rodina systémů GIS. b ) systémy flat souborů - samostatné uložení geometrických a prostorových dat v samostatných prostředích a jejich spojení jen v případě potřeby - geometrie objektů je uložena ve speciálním prostředí společně s identifikátorem, který poskytuje spojení na prostor, kde jsou uloženy atributy. Jednotlivý objekt (jednotlivá geometrie) může mít pouze jediný identifikátor, ale více atributů. K získání informací o objektech je třeba vstoupit do obou prostředí. Nejzákladnější formou, ve které mohou být uchovávána atributová data , je použití tzv. flat souborů, což jsou jednoduché tabulky. Nevýhodou tohoto způsobu ukládání geografických dat je rozdílný standard pro uložení geometrických i atributových dat, protože každý systém má svůj formát. Některými autory (např. Maguire, Goodchild, Rhind, 1991) je tato strategie ukládání dat označována jako “hybridní koncepce” a považují ji za již překonanou.
- GIS „druhé generace“ (se systémem SŘBD) - samostatné uložení geometrických a prostorových dat v jediné databázi - geometrie i atributy jsou uloženy v jediné databázi jako oddělené soubory. Tento způsob uložení dat využívá většina běžných současných GIS. Určité problémy způsobuje uložení topologických informací. Někdy bývá tento způsob označován jako “koncepce vylepšených DBMS”. Hlavním dělícím kritériem mezi těmito systémy je, že některé z nich používají relační SŘBD (RSŘBD) pouze pro ukládání atributů a dávají přednost svému vlastnímu SW pro správu prostorových dat, zatímco jiné používají RSŘBD pro ukládání jak geometrických dat, tak i atributů. První skupina je označována jako duální systémy, druhá jako systémy integrovaných architektur.
Obrázek č. xx znázorňuje běžné metody propojování atributů s prostorovými entitami, které mají unikátní identifikátory v souborech geografických dat a tyto identifikátory jsou též používány jako hodnoty primárních klíčů v relačních tabulkách. Předností použití systému RSŘBD pro správu atributů v programu GIS je odstranění nutnosti jakékoliv duplikace atributů a možné propojení s ostatními datovými tabulkami prostřednictvím cizích klíčů. Prostorová a atributová data jsou však data různého charakteru. Prostorová data jsou mnohem komplexnější než atributová, použití RSŘBD pro ukládání takovýchto dat proto naráží na mnohé problémy.
- duální systémy – systémy ARC/INFO, MGE a Geo/SQL jsou příklady systémů GIS, které podporují duální architekturu a používají přitom zakoupený SW RSŘBD pro správu atributů a na jeho propojení s vlastním programem, který spravuje prostorová data. Modelovou architekturu duálních systémů znázorňuje obrázek č. 10. Díky své dualitě mohou mít tyto systémy problémy s integritou dat a mají také problémy s bezešvými daty (databáze dělena do mapových listů, což přináší problémy především z hlediska udržení topologie v modelu).
- integrované systémy – systémy, které integrují do společné struktury RSŘBD jak prostorová, tak atributová data – např. SYSTEM 9, SDE (Spatial Database Engine), GeoMedia nebo ARC/INFO s modulem ArcStorm – aby tyto programy mohly ukládat prostorová data v systému SŘBD, musely překonat řadu obtíží, spojených s charakterem prostorových dat, což bylo v praxi vyřešeno použitím nadstavby k základnímu relačnímu modelu. O management dat se tedy stará middleware, což je produkt tvořící komunikační vrstvu mezi databází a GIS SW, ne databáze samotná. Díky uložení prostorové části v databázi je možné pracovat s bezešvými prostorovými daty (odpadá dělení prostoru na mapové listy). Nevýhodou modelu je jeho relativní pomalost, díky tomu, že relační databáze neumí efektivně ukládat prostorová data. I tyto systémy mohou mít problémy s integritou dat.
- GIS „třetí generace“ – objektový model – např. Smallworld - uložení geometrických a prostorových dat v jediné databázi společně jako prostorové objekty - jedním ze způsobů, jak realizovat tuto strategii je např. objektově orientované programování. Tento typ programování umožňuje ukládat, spojovat, prohledávat, manipulovat a analyzovat informace uložené v relačním zdroji bez potřeby speciální databáze, bez potřeby jakéhokoliv překladu nebo konverze dat a bez potřeby ukládat topologii v databázi zvláštním způsobem. Prostorové objekty definované objektově-orientované databázi obsahují geometrii i atributový popis. Pro objekty jsou definované přípustné operace. Příkazy se provádějí posíláním “zpráv” všem objektům. Na tyto zprávy odpovídají pouze ty objekty, pro které je daná operace přípustná. Podobjekty dědí chování, ale mohou mít i další vlastnosti. Model nemá problémy s integritou (je řešena na úrovni objektu).
6.4 Dotazovací jazyky
Typy dotazů, které umožňuje hierarchický a síťový databázový model jsou definovány již ve fázi návrhu struktury databáze.
Zapsaná propojení v datových záznamech jsou používána k procházení - orientaci v databázi. Z toho plyne to, že pokud chceme hledat v databázi, musíme znát hierarchii, ve které jsou data uložena. Jazyky, které vyžadují, aby uživatel znal hierarchii databáze označujeme jako procedurální dotazovací jazyky.
Relační databáze dosahují výrazně větší flexibility odbouráním hierarchie atributů. Každý atribut v nich může být použit jako klíč k hledání informace a data v samostatných tabulkách mohou být vztažena a spojena s využitím kteréhokoliv atributového pole, které je společné nebo které obsahuje všechny atributy. Oproti hierarchických a síťovým datovým strukturám jsou v relačních strukturách vztahy explicitně zakódovány v databázi. Relační model tedy neomezuje rozsah dotazů a uživatel nemusí znát strukturu databáze. Dotazovací jazyk tak není závislý na struktuře dat. Takovéto jazyky označujeme jako neprocedurální dotazovací jazyky. Jsou velmi populární a rozšířené. Pravděpodobně nejznámějším zástupcem této skupiny dotazovacích jazyků je SQL (Standard Query Language) vyvinutý společností IBM.
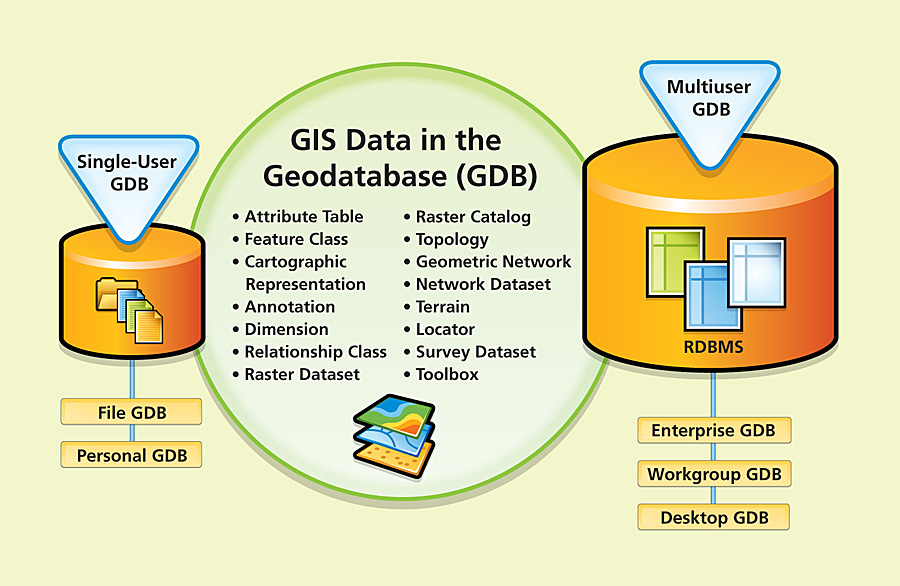
6.5 Geodatabáze
Geodatabáze je prostorová databáze navržená pro ukládání, dotazování a manipulaci s geografickými informacemi a prostorovými daty. Geodatabáze je proprietární formát vyvinutý firmou esri. Toto pracovní prostředí spravuje jak vektorová tak rastrová data. Geodatabáze je přirozená datová struktura systému ArcGIS a je primárním datovým formátem používaným pro editaci a správu dat.
Model úložiště geodatabáze je založen na řadě jednoduchých, ale nezbytných konceptů relačních databází a využívá silných stránek základního systému správy databází (DBMS). Jednoduché tabulky a dobře definované typy atributů se používají k ukládání dat schémat, pravidel, základů a prostorových atributů pro každý soubor geografických dat. Tento přístup poskytuje formální model pro ukládání a práci s vašimi daty. Tímto přístupem lze strukturovaný dotazovací jazyk (SQL) - řadu relačních funkcí a operátorů - použít k vytváření, úpravám a dotazovacím tabulkám a jejich datovým prvkům.

Obrázek 1: koncept geodatabáze (zdroj: https://www.esri.com/news/arcnews/winter0809articles/winter0809gifs/p1p2-lg.jpg)
{kind=link}
Geodatabáze je implementována pomocí stejné vícevrstvé aplikační architektury jako v jiných pokročilých aplikacích DBMS; při jeho provádění není nic exotického ani neobvyklého. Víceúrovňová architektura geodatabáze je někdy označována jako objektově relační model. Objekty geodatabázy přetrvávají jako řádky v tabulkách DBMS, které mají identitu, a chování je dodáváno prostřednictvím aplikační logiky geodatabáze. Oddělení aplikační logiky od úložiště umožňuje podporu několika různých DBMS a datových formátů.
Klíčový pojem geodatabáze je datová sada (angl. dataset). Datová sada je primární mechanismus k organizaci a užívání geografických informací v ArcGIS. Rozlišujeme tři základní typy:
- Osobní geodatabáze (Personal geodatabase) - datový formát pro geodatabáze ArcGIS uložený a spravovaný v souborech Microsoft Access (*.mdb). Celý obsah geodatabáze je uložen v jednom souboru MS Access. Tento typ uložení dat limituje velikost geodatabáze na 2GB. Efektivní limit před snížením výkonu je mezi 250 a 500 MB na jeden soubor MS Access. Pro znalce a uživatele Microsoft Access je to dobrá možnost využití databáze s geografickými daty. Geodatabáze obsahuje tabulky s třídami prvků a systémové tabulky obsahující informace o pokročilých možnostech geodatabází – subtypy, domény, relace atd. Tento typ geodatabáze podporuje více čtenářů a pouze jednoho editora. Jednou z výhod geodatabáze je automatický výpočet geometrických veličin – délka liniových prvků, obvod a výměra polygonových prvků. Jedná se o dynamickou hodnotu, která se při změně geometrie prvku aktualizuje.
- Souborová geodatabáze (File geodatabase) - Tento typ geodatabáze je uložen jako adresář na disku v souborovém systému. Každá datová sada je udržována jako soubor, který může dosahovat velikosti až 1 TB. Limit 1 TB je možné navýšit na 256 TB pro extrémně velké rastrové datové sady. Oproti osobní geodatabázi redukuje místo zabírající na disku o 50–75 %. Tento typ geodatabáze je upřednostňován před osobní geodatabází. Podporuje více čtenářů a jednoho editora, avšak více editorů u více datových sad. Souborová geodatabáze určitým způsobem zabezpečuje data, protože ji nelze otevřít v jiném programu než pomocí ArcGIS. Umožňuje také ukládat data v komprimovaném formátu pouze pro čtení, který snižuje i požadavky na potřebné místo pro uložení. Stejně jako osobní geodatabáze se i souborová geodatabáze vyznačuje automatickým výpočtem geometrických veličin jednotlivých prvků, linií a polygonů.
- ArcSDE geodatabase - geodatabázi uloženou v relační databázi využívající Oracle, Microsoft SQL Server, IBM DB2, IBM Informix nebo PostgreSQL. Tyto víceuživatelské geodatabáze vyžadují k použití ArcSDE a mohou pracovat na neomezené velikosti s neomezeným počtem uživatelů. Soubor různých datových sad, které jsou udržovány jako tabulky v relační databázi. ArcSDE geodatabáze podporuje čtení a editaci více uživatelů. Nejedná se o geodatabázi volně a zadarmo dostupnou v ArcGIS.
Limity velikosti se odvíjejí od limitů SŘBD.
6.5.1 Uložení geodatabáze v relačních databázích
Jádrem geodatabáze je standardní schéma relační databáze (řada standardních databázových tabulek, typů sloupců, indexů a dalších databázových objektů). Schéma přetrvává ve sbírce systémových tabulek geodatabáze v DBMS, která definuje integritu a chování geografických informací. Tyto tabulky jsou uloženy jako soubory na disku nebo v obsahu DBMS, jako je Oracle, IBM DB2, PostgreSQL, IBM Informix nebo Microsoft SQL Server.
Dobře definované typy sloupců se používají k ukládání tradičních tabulkových atributů. Když je geodatabáza uložena v DBMS, jsou prostorové reprezentace, nejčastěji reprezentované vektory nebo rastry, obecně ukládány pomocí rozšířeného prostorového typu.
V geodatabázi jsou ukládány dvě primární sady tabulek: systémové tabulky a tabulky datových sad.
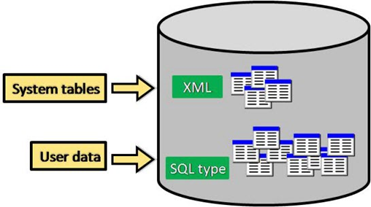
Obrázek 2: typy tabulek v geodatabázi
- tabulky datových sad (dataset tables) - každý datový soubor v geodatabáze je uložen v jedné nebo více tabulkách. Tabulky datových sad spolupracují se systémovými tabulkami pro správu dat.
- systémové tabulky (systém tables) - systémové tabulky geodatabáze sledují obsah každé geodatabáze. V podstatě popisují schéma geodatabáze, které specifikuje všechny definice datových sad, pravidla a vztahy. Tyto systémové tabulky obsahují a spravují všechna metadata potřebná k implementaci vlastností geodatabáze, pravidel ověření dat a chování.
V geodatabázi jsou atributy spravovány v tabulkách na základě řady jednoduchých, ale nezbytných konceptů relačních dat:
- Tabulky obsahují řádky.
- Všechny řádky v tabulce mají stejné sloupce.
- Každý sloupec má datový typ, například celé číslo, desetinné číslo, znak a datum.
- K dispozici je řada relačních funkcí a operátorů (jako je SQL), které pracují s tabulkami a jejich datovými prvky.
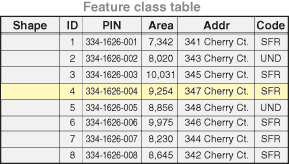
Obrázek 2: struktura tabulky
Tabulky a vztahy hrají v ArcGIS klíčovou roli, stejně jako v tradičních databázových aplikacích. Řádky v tabulkách lze použít k uložení všech vlastností geografických objektů. To zahrnuje držení a správu geometrie prvku ve sloupci Tvar.
Obrázek 3 ukazuje dvě tabulky a to, jak mohou být jejich záznamy vzájemně propojeny pomocí společného pole.
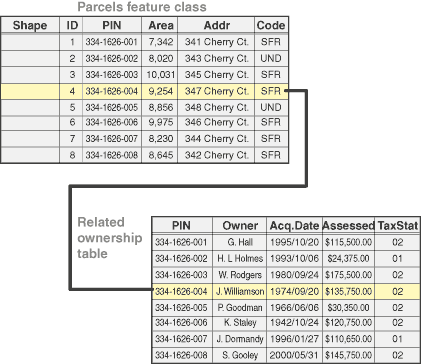
Obrázek 3: propojení tabulek
6.5.1.1 Typy atributových dat v geodatabázi
Existuje několik podporovaných typů sloupců používaných k držení a správě atributů v geodatabáze. Dostupné typy sloupců zahrnují různé typy čísel, text, datum, binární velké objekty (BLOB) a globálně jedinečné identifikátory (GUID). Mezi podporované typy sloupců atributů v geodatabáze patří:
- Čísla: Může to být jeden ze čtyř číselných datových typů: krátká celá čísla, dlouhá celá čísla, čísla s plovoucí desetinnou čárkou s jednoduchou přesností (často označovaná jako plováky) a čísla s plovoucí desetinnou čárkou s dvojitou přesností (běžně nazývaná zdvojnásobení).
- Text: Jakákoli sada alfanumerických znaků určité délky.
- Datum: Obsahuje data a čas.
- BLOB: Binární velké objekty se používají k ukládání a správě binárních informací, jako jsou symboly a geometrie CAD.
- Globální identifikátory: Datové typy GlobalID a GUID ukládají řetězce stylů registru skládající se z 36 znaků uzavřených v složených závorkách. Tyto řetězce jedinečně identifikují prvek nebo řádek tabulky v geodatabáze a napříč geodatabázami. Tito jsou velmi zvyklí na správu vztahů obzvláště pro správu dat, verzování, aktualizace jen změny a replikace. Typy sloupců XML jsou podporovány také prostřednictvím programovacích rozhraní. Sloupec XML může obsahovat jakýkoli formátovaný obsah XML (například metadata XML).
Rozšiřující tabulky
Tabulky poskytují popisné informace o prvcích, rastrech a tradičních atributových tabulkách v geodatabáze. Uživatelé provádějí mnoho tradičních tabulkových a relačních operací pomocí tabulek.
V geodatabáze existuje cílená sada funkcí, které se volitelně používají k rozšíření možností tabulek. Mezi ně patří následující:
- atributové domény (Attribute domains) - specifikace domén jednotlivých atributů (nastavení hodnot, kterých mohou konkrétní atributy nabývat) - vhodné pro zajištění integrity databáze,
- třídy vztahů (Relationship classes) - nastavení vztahu mezi dvěma tabulkami (propojení, spojení) pomocí společného klíče - vyhledá řádky druhé tabulky v daném vztahu k řádkům první tabulky,
- subtypy (Subtypes) - organizace podtříd v tabulce - je často využíváno tehdy, když se různé podmnožiny jedné třídy prvků chovají odlišným způsobem,
- versování (Versioning) - správa dlouhých aktualizačních transakcí, historických archivů a víceuživatelských úprav vyžadovaných v pracovních postupech GIS.
6.5.2 Třídy prvků (feature classes)
Třídy prvků jsou homogenní kolekce společných prvků, z nichž každá má stejnou prostorovou reprezentaci, jako jsou body, čáry nebo mnohoúhelníky, a společná sada sloupců atributů, například třída rysů čar pro znázornění střednic silnic. Čtyři nejčastěji používané třídy funkcí jsou body, čáry, polygony a anotace (název geodatabáze pro text mapy).
Na obrázku 4 je zobrazeno využití čtyř datových sad pro k reprezentaci stejné oblasti: (1) umístění poklopů jako body, (2) kanalizační linie, (3) polygony pozemků a (4) anotace názvů ulic.
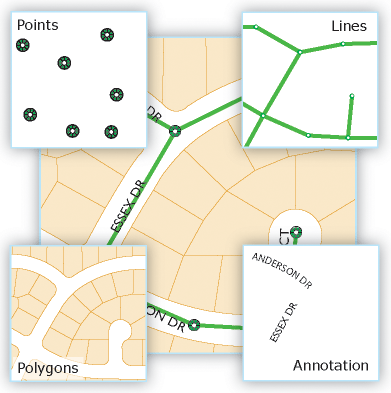
Obrázek 4: propojení tabulek
Z obrázku 4 je patrný potenciální požadavek modelovat některé pokročilé vlastnosti prvku. Například kanalizační vedení a umístění průlezů tvoří síť kanalizačních sítí, systém, pomocí kterého můžete modelovat odtok a toky. Také si všimněte, jak sousední pozemky sdílejí společné hranice. Většina uživatelů balíků chce udržovat integritu hranic sdílených funkcí ve svých datových sadách pomocí topologie.
Jak již bylo zmíněno, uživatelé často musí modelovat takové prostorové vztahy a chování ve svých geografických datových sadách. V těchto případech můžete tyto základní třídy funkcí rozšířit přidáním řady pokročilých prvků geodatabáze, jako jsou topologie, síťové datové sady, terény a lokátory adres.
Další informace o přidávání těchto pokročilých chování do geodatabáz naleznete v části Rozšíření funkcí.
Typy tříd prvků
Vektorové prvky (geografické objekty s vektorovou geometrií) jsou univerzální a často používané typy geografických dat, vhodné pro reprezentaci prvků s diskrétními hranicemi, jako jsou ulice, stavy a pozemky. Objekt je objekt, který ukládá svou geografickou reprezentaci, což je obvykle bod, čára nebo mnohoúhelník, jako jedna ze svých vlastností (nebo polí) v řádku. V ArcGIS jsou třídy prvků homogenní kolekce prvků se společnou prostorovou reprezentací a sadou atributů uložených v databázové tabulce, například třída liniových prvků pro reprezentaci střednic silnic.
Poznámka: Při vytváření třídy prvků budete vyzváni, abyste nastavili typ prvků pro definování typu třídy prvků (bod, čára, mnohoúhelník atd.).
Obecně jsou třídy funkcí tematické kolekce bodů, čar nebo polygonů, existuje však sedm typů tříd funkcí. První tři jsou podporovány v databázích a geodatabázích. Poslední čtyři jsou podporovány pouze v geodatabázích:
- body = prvky, které jsou příliš malé na to, aby mohly reprezentovat jako čáry nebo mnohoúhelníky, stejně jako umístění bodů (například GPS pozorování).
- čáry - představují tvar a umístění geografických objektů, jako jsou středy ulic a potoky, příliš úzké, aby mohly být znázorněny jako oblasti. Čáry se také používají k reprezentaci prvků, které mají délku, ale žádnou plochu, jako jsou kontury a hranice.
- polygony - sady mnohostranných prvků oblasti, které představují tvar a umístění homogenních typů prvků, jako jsou státy, okresy, pozemky, typy půdy a zóny využití půdy.
- anotace - Mapujte text včetně vlastností, jak se text vykresluje. Například, kromě textového řetězce každé anotace, jsou zahrnuty další vlastnosti, jako jsou body tvaru pro umístění textu, jeho písmo a velikost bodu a další vlastnosti zobrazení. Anotace může být také propojena s funkcemi a může obsahovat podtřídy.
- dimenze - zvláštní druh anotace, která ukazuje specifické délky nebo vzdálenosti, například k označení délky strany budovy nebo hranice pozemku nebo vzdálenosti mezi dvěma prvky. Rozměry jsou velmi používány v projektech, strojírenství a aplikacích pro GIS;
- multibody (multipoints) - se skládají z více než jednoho bodu. Multipoints jsou často používány ke správě polí velmi velkých bodových sbírek, jako jsou seskupení bodů lidar, které mohou obsahovat doslova miliardy bodů. Použití jediného řádku pro takovou geometrii bodu není možné. Jejich seskupení do vícebodových řádků umožňuje geodatabáze zpracovat masivní sady bodů.